
anything-api
Any website. We deliver the API.
Anything API Wants to Give Every Website an API Whether They Like It or Not
The Macro: The Web Is Still Mostly Closed
Here’s a thing that doesn’t get talked about enough. The web has been around for thirty-plus years, and the majority of sites on it still don’t have public APIs. You want structured data from a retailer’s product page, or a news outlet’s archive, or some niche government database? Good luck. You’re either scraping raw HTML with something held together by regex and prayers, or you’re paying for a middleware service that may or may not still work when the target site redoes its nav.
This is not a new problem. Scraping infrastructure has existed in various forms for decades. Apify, Browserless, Playwright-based cloud runners, even older headless browser setups all exist precisely because developers kept needing to automate browser interactions that sites never officially supported. The market for “give me the data that lives on this page” is real and has been real for a while.
What’s changed is the agent layer. AI that can interpret natural language instructions, navigate a UI, and execute multi-step browser tasks without a human writing every XPath selector is genuinely new. I’ve covered adjacent stuff here, like how Chowder is thinking about AI agent deployment as the actual hard problem and how ZenMux is trying to unify the API abstraction layer entirely. Both point at the same underlying shift: the plumbing for AI-driven web access is getting productized fast.
The competitors in the scraping-to-API space aren’t sitting still either. Apify has a massive library of pre-built actors. Browserless offers raw browser infrastructure. A dozen smaller tools promise “scrape anything” with varying levels of structure in the output. The real question is whether agent-generated, production-ready endpoints are a meaningful step up from that, or just a better-looking wrapper.
I think it might actually be a step up. But I want to explain why that’s not obvious.
The Micro: Agents Writing APIs on Your Behalf
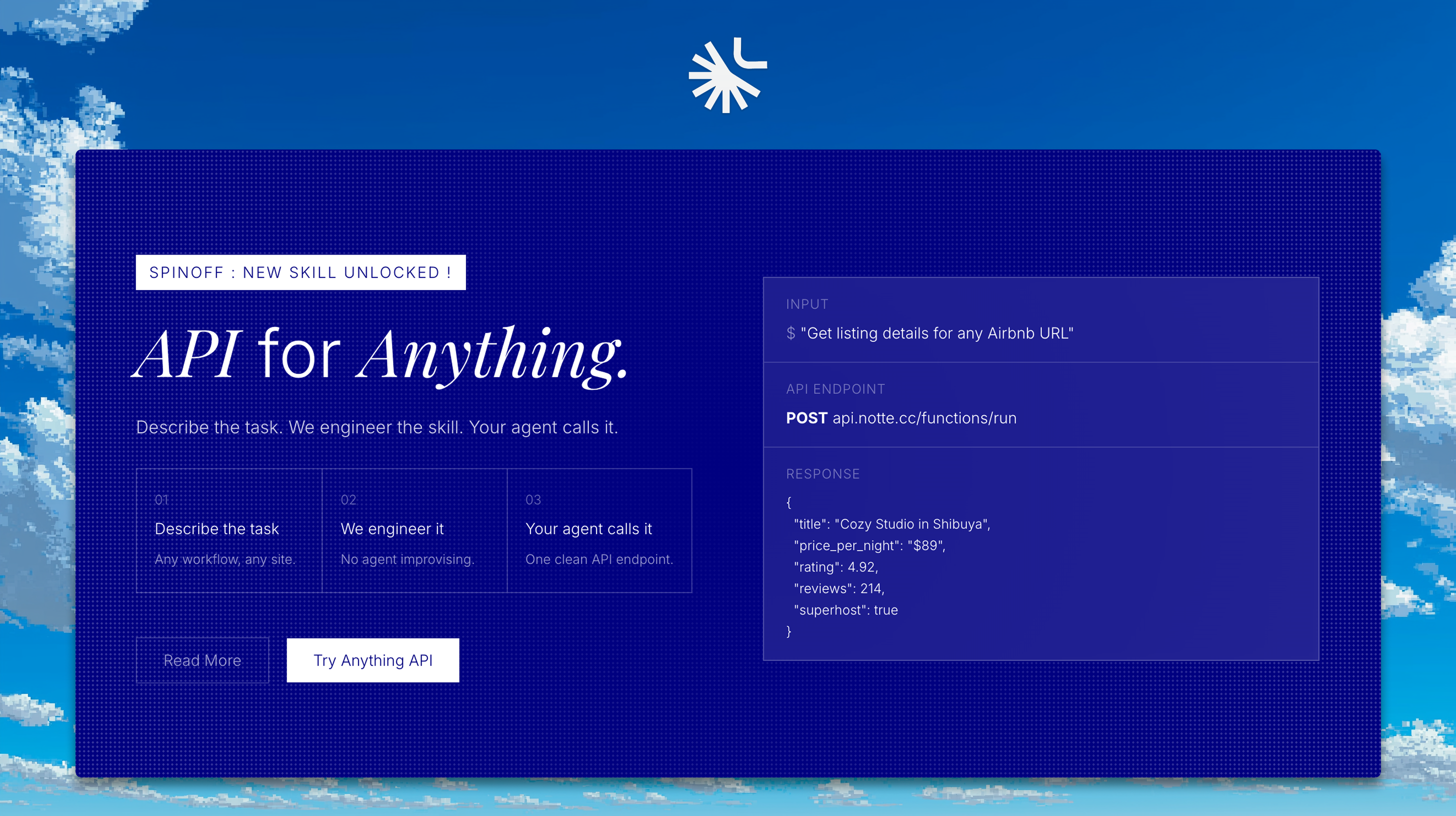
The core idea behind Anything API (built on top of their Notte agent platform) is straightforward in a way that either sounds brilliant or slightly scary depending on your background. You describe what you want. Their agents go figure out how to do it against the live website. You get back a deployable function endpoint.
Not a scraper. Not a raw HTML dump. An endpoint. One you can schedule via Cron, call directly, or deploy serverless. That’s the product decision I find most interesting. They’re not selling you access to data, they’re selling you infrastructure. The output is code-shaped, not data-shaped.
This matters more than it sounds. If you’ve ever built a scraper for production use (and I have, it’s not fun), you know the problem isn’t getting the data once. It’s maintenance. Sites change. Selectors break. Sessions expire. The ongoing cost of keeping a scraper alive is often higher than the cost of building it. What Anything API is implicitly promising is that the agent layer absorbs some of that maintenance burden, because the agent understands intent, not just a hardcoded CSS path.
The workflow, as far as I can tell from the site, is describe your task in plain language, let their agents build the function, then receive an endpoint you can actually use in production. The “Notte” branding is their underlying agent framework. Whether the agent-generated code is readable, auditable, or modifiable after the fact is something I’d want to dig into before shipping anything sensitive through it.
It did well when it launched, landing at the top of the charts and pulling in strong engagement across comments.
The categories they highlight on the site (research, shopping, finance, news, developer tools) tell you a lot about who they’re pitching. These are exactly the verticals where data exists publicly but APIs don’t.
The Verdict
I’m genuinely interested in this one, with some caveats.
The value proposition is real. Developers do waste enormous amounts of time building and maintaining browser automation that sites never intended to support. If Anything API can make that fast and reliable, that’s a real product for a real pain point. I’ve seen similar API abstraction bets get complicated fast, though, especially when the underlying targets keep moving.
The things I’d want to know at 30 days: How often do generated endpoints break when a target site updates? What does the error handling look like? Is there any versioning or monitoring built in, or does “production-ready” mean something generous here?
At 60 days: Who’s actually paying? This feels like a developer tool that sells itself on the bottom-up motion, individual devs discovering it, building something, then bringing it to a team. That can work, but the unit economics need to close before the free tier gets expensive to run.
At 90 days: Does the agent layer actually hold up under load and site variation, or does it work great on a demo site and then quietly degrade on anything with aggressive bot detection?
I want this to be as good as the pitch. The pitch is very good.