
byterover-memory-system-for-openclaw
File-based memory for OpenClaw with >92% retrieval accuracy
ByteRover Thinks Your AI Agent's Memory Problem Is Actually a File System Problem
The Macro: The Agent Amnesia Tax Is Getting Old
Here’s the thing about stateful AI agents that most demos conveniently skip over. They forget. You run a session, the context window fills up or closes, and the next time you spin it back up it’s like talking to someone with full amnesia. Every time. The whole pitch of agentic AI is that it works autonomously over time, but the memory infrastructure to actually support that has been an afterthought.
Vector databases became the default answer to this. Embed your context, store the embeddings, retrieve semantically at query time. It works okay. It works okay in the same way that a sticky note works okay as a filing system. The retrieval is fuzzy in ways that matter when you’re asking an agent to reason over weeks of accumulated context, not just find the closest sentence to a query.
The open source developer tooling space is genuinely enormous right now. According to multiple market research sources, the open source services market sits somewhere between $37 billion and $46 billion in 2025, depending on how you slice it, with projections pointing toward triple-digit billions by the early 2030s. That’s not a niche. That’s infrastructure-scale money, and a lot of it is chasing the agentic AI layer specifically.
The competitors in this space are scattered. Some are baked into specific agent frameworks and don’t travel well. Some are cloud-only, which is a non-starter for developers who care about where their context actually lives. Tools like Cline have been pushing hard on the idea that agents should live inside your actual workflow, and the memory question is the logical next problem that approach surfaces. Nobody has nailed a portable, accurate, local-first answer yet. ByteRover is making a specific argument that they have one.
The Micro: A File Tree Where Your Agent’s Brain Lives
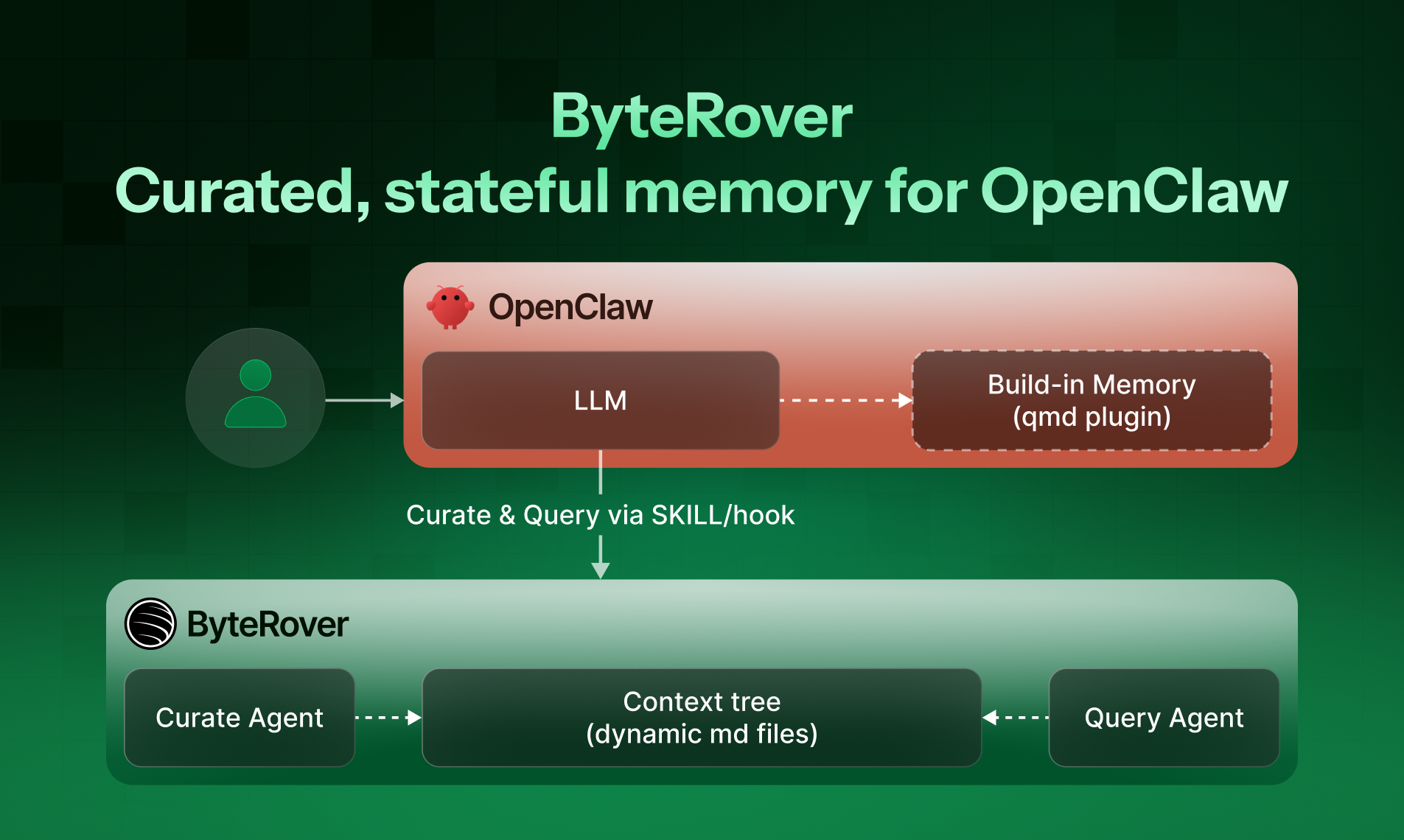
ByteRover is a memory layer for OpenClaw agents, and its core architectural bet is that file-based retrieval beats vector-based retrieval for this use case. That’s the actual thesis, and it’s more interesting than it sounds.
Instead of embedding your context into a vector database and hoping semantic similarity gets you the right chunk back, ByteRover builds a hierarchical knowledge tree out of your memory in natural language files. Retrieval works in tiers: fuzzy text search first, then deeper LLM-driven search if that doesn’t surface what you need. The claim is 92.19% retrieval accuracy, which the team positions as best on the market. They published a benchmark post on their blog for anyone who wants to stress-test that number themselves.
The local-first default matters here. Everything runs on your machine unless you decide otherwise. If you want to push to their cloud, sync to another machine, or share memory state with a teammate, you can. Version-controlled. Editable. It’s a design philosophy closer to how developers actually think about their own files than how most AI memory tools have been built.
Shared memory across multiple OpenClaw agents is built in. That’s not a footnote feature. If you’re running a multi-agent setup, the agents are working from the same persistent, structured memory rather than each maintaining their own siloed context. That has real implications for the kind of long-running, compound tasks that agentic setups are theoretically supposed to handle.
The tool also works with any LLM provider, which means you’re not locked into their model choices. You bring the API key, you control cost and observability. That’s the right call for a developer-focused product.
It picked up over 26,000 downloads in its first week according to the product’s own description, and got solid traction when it launched. The install is a single curl command, which for this audience is basically the whole first impression.
The Verdict
I’m interested in this one, genuinely. The architectural argument, file-based over vector-based, is specific enough to evaluate and weird enough to be worth watching. Most memory tools for agents feel like features bolted onto something else. ByteRover feels like someone actually sat with the problem of agent amnesia and came back with a different answer than everyone else.
The 30-day question is whether the 92% accuracy claim holds outside of their own benchmark conditions. Benchmarks are easy to design favorably. Real-world retrieval across messy, accumulated, contradictory context is harder, and I’d want to see community usage reports before treating that number as settled.
The 60-day question is adoption stickiness. Twenty-six thousand downloads in a week is a real signal, but developer tools often get high initial installs from curious people who never build anything with them. Retention in actual production pipelines is what matters.
For a broader take on where developer-facing AI tooling is heading, the OpenUI project’s approach to standardization is worth reading alongside this. The portability story ByteRover is telling, memory that travels across tools rather than living in one, points toward the same direction.
If the benchmark holds up in the wild and the cloud sync stays reliable, this fills a real gap. If the retrieval accuracy degrades on messy real-world context, it’s just a prettier vector store with extra steps. I want to know which one it is in about six weeks.